

Parallelism in software is the execution of instructions simultaneously. Each programming language either implements their own libraries, or provide native support as part of the language, like Go. Parallelism allows software engineers to side-step the physical limitations of the hardware by executing tasks in parallel on multiple processors.1
The parallelism of an application is dependent on the skill of the engineer building the software due to the complexity in properly utilizing the building blocks of parallelism.
Examples of parallel tasks:
- Multiple people taking orders at a restaurant
- Multiple cashiers at a grocery store
- Multi-Core CPUs
In reality there are multiple layers of parallelism in any application. There is the parallelism of the application itself, which is defined by the application developer, and there is the parallelism (or multiplexing) of the instructions executed by the CPU on the physical hardware orchestrated by the operating system.
NOTE: In general applications must be explicitly written such that they perform actions in parallel. This requires engineers to have skills in writing “correct” parallelizable code.
Table Of Contents
Building Blocks of Parallelism
Application developers utilize abstractions to describe the parallelism of an application. These abstractions are generally different in every language where parallelism is implemented but the concepts are the same. In C, for example, parallelism is defined by the use of pthreads and in Go, parallelism is defined by the use of goroutines.
Processes
A process is a single unit of execution which includes its own “program counter, registers and variables. Conceptually, each process has it’s own virtual CPU”2 This is important to understand because of the overhead incurred by the creation and management of a process. Along with the overhead of creating a process, each process only has access to it’s own memory. This means that the process can’t access other processes’ memory.
This is a problem if there are multiple threads of execution (parallel tasks) which need access to some shared resource.
Threads
Threads were introduced as a means of granting access to shared memory within the same process but on different parallel execution units. Threads are almost their own process but have access to the shared address space of the parent process.
Threads have far less overhead than processes because of the fact that they do not have to create a new process for each thread and resources can be shared or reused.
Here is an example for Ubuntu 18.04 comparing the overhead of forking a process and a creating a thread:3
1# Borrowed from https://stackoverflow.com/a/52231151/834319
2# Ubuntu 18.04 start_method: fork
3# ================================
4results for Process:
5
6count 1000.000000
7mean 0.002081
8std 0.000288
9min 0.001466
1025% 0.001866
1150% 0.001973
1275% 0.002268
13max 0.003365
14
15Minimum with 1.47 ms
16------------------------------------------------------------
17
18results for Thread:
19
20count 1000.000000
21mean 0.000054
22std 0.000013
23min 0.000044
2425% 0.000047
2550% 0.000051
2675% 0.000058
27max 0.000319
28
29Minimum with 43.89 µs
30------------------------------------------------------------
31Minimum start-up time for processes takes 33.41x longer than for threads.
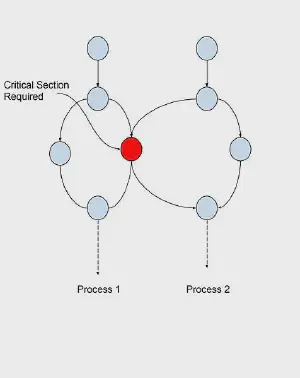
Critical Sections
Critical sections are shared memory sections which are needed by various parallel tasks within a process. These sections may be shared data, types, or other resources. (See example to the right4)
Complications of Parallelism
Since a processes threads execute in the same memory space, there is a risk of critical sections being accessed by multiple threads at the same time. This can cause data corruption or other unexpected behavior in the application.
There are two primary problems that occur when multiple threads access shared memory at the same time.
Race Conditions
A race condition is where multiple parallel threads of execution are directly reading or writing to a shared resource without any protections. This can lead to situations where the data stored within the resource can be corrupted or lead to other unexpected behavior.
For example, imagine a process where a single thread is reading a value from a shared memory location and another thread is writing a new value to the same location. If the first thread reads the value before the second thread writes the value, the first thread will read the old value.
This leads to a situation where the application is not behaving as expected.
Deadlocks
A deadlock occurs when two or more threads are waiting for each other to do something. This can lead to the application hanging or crashing.
An example is a situation where one thread executes against a critical section waiting for a condition to be met and another thread is executing against the same critical section and is waiting for a condition from the other thread to be met. If the first thread is waiting for a condition to be met and the second thread is waiting for the first thread, both threads will wait forever.

A second form of deadlock can occur when attempting to protect against race conditions by using mutual exclusion locks
Barriers
Barriers are synchronization points which manage access to shared resources or critical regions from multiple threads within a process.
These barriers allow the application developer to control parallel access to ensure that the resources are not accessed in an unsafe manner.
Mutual Exclusions Locks (Mutexes)
Mutexes are a type of barrier that allow only one thread to access a shared resource at a time. This is useful for preventing race conditions through the locking an unlocking when reading or writing to a shared resource.
1// Example of a mutex barrier in Go
2import (
3 "sync"
4 "fmt"
5)
6
7var shared string
8var sharedMu sync.Mutex
9
10func main() {
11
12 // Start a goroutine to write to the shared variable
13 go func() {
14 for i := 0; i < 10; i++ {
15 write(fmt.Sprintf("%d", i))
16 }
17 }()
18
19 // read from the shared variable
20 for i := 0; i < 10; i++ {
21 read(fmt.Sprintf("%d", i))
22 }
23}
24
25func write(value string) {
26 sharedMu.Lock()
27 defer sharedMu.Unlock()
28
29 // set a new value for the `shared` variable
30 shared = value
31}
32
33func read() {
34 sharedMu.Lock()
35 defer sharedMu.Unlock()
36
37 // print the critical section `shared` to stdout
38 fmt.Println(shared)
39}
If we look at the above example, we can see that the shared variable is
protected by a mutex. This means that only one thread can access the shared
variable at a time. This ensures that the shared variable is not corrupted and
that there is predictable behavior.
NOTE: When using Mutexes it is critical to ensure that the mutex is released when the function returns. In Go, for example, this is done by using the
deferkeyword. This ensures that other threads can access the shared resource.
Semaphores
Semaphores are a type of barrier that allow only a certain number of threads to access a shared resource at a time. This is different from a mutex in that the number of threads that can access the resource are not limited to one.
There is not a semaphore implementation in the Go standard library. However, it can be implemented using channels.5
Busy Waiting
Busy waiting is a technique where a thread is waiting for a condition to be met. Generally this is used to wait for a counter to reach a certain value.
1// Example of Busy Waiting in Go
2var x int
3
4func main() {
5 go func() {
6 for i := 0; i < 10; i++ {
7 x = i
8 }
9 }()
10
11 for x != 1 { // Loop until x is set to 1
12 fmt.Println("Waiting...")
13 time.Sleep(time.Millisecond * 100)
14 }
15}
So busy waiting entails a loop that is waiting for a condition to be met which reads or writes to a shared resource and must be guarded by a mutex to ensure correct behavior.
The problem with the above example is that the loop is accessing a critical
section which is not protected by a mutex. This can lead to race conditions
where the loop may access the value but it may have been changed by another
thread of the process. In fact, the above example is a good example of a race
condition as well. It’s possible this application will NEVER exit because
there is no guarantee that the loop will be fast enough to read the value of x
while it is still 1 which means that the loop will never exit.
If we were to guard the variable x with a mutex, the loop would be guarded
and the application would exit, but this is still not perfect and the loop
setting x could still be fast enough to hit the mutex twice before the loop
reading the value could execute (though unlikely).
1import "sync"
2
3var x int
4var xMu sync.Mutex
5
6func main() {
7 go func() {
8 for i := 0; i < 10; i++ {
9 xMu.Lock()
10 x = i
11 xMu.Unlock()
12 }
13 }()
14
15 var value int
16 for value != 1 { // Loop until x is set to 1
17 xMu.Lock()
18 value = x // Set value == x
19 xMu.Unlock()
20 }
21}
In general busy waiting is not a good idea. It is better to use a semaphore or a mutex to ensure that the critical section is protected. We’ll cover better ways to handle this in Go but it illustrates the complexities of writing “correct” parallelizable code.
Wait Groups
Wait groups are method for ensuring that all parallel code paths have completed
processing prior to continuing. In Go, this is done by using a sync.WaitGroup
which is provided in the sync package of the standard library.
1// Example of a `sync.WaitGroup` in Go
2import (
3 "sync"
4)
5
6func main() {
7 var wg sync.WaitGroup
8 var N int = 10
9
10 wg.Add(N)
11 for i := 0; i < N; i++ {
12 go func() {
13 defer wg.Done()
14
15 // do some work
16 }()
17 }
18
19 // wait for all of the goroutines to finish
20 wg.Wait()
21}
In the example above the wg.Wait() is a blocking call. This means that the
main thread will not continue until all of the goroutines have finished and
their cooresponding defer wg.Done() has been called. Internally, the WaitGroup
is a counter that is incremented by one for each goroutine that is added to the
WaitGroup where wg.Add(N) is called. When the counter reaches zero, the main
thread will continue processing or in this case the application will exit.
What is Concurrency?
Concurrency and Parallelism are often conflated. To better understand the difference between concurrency and parallelism, let’s look at an example of concurrency in the real world.
If we use a restaurant as an example there are several different groups of work types (or replicable procedures) that that take place in a restaurant.
- Host (responsible for seating guests)
- Wait Staff (responsible for taking orders, and serving food)
- Kitchen (responsible for cooking food)
- Bussers (responsible for clearing tables)
- Dishwasher (responsible for cleaning up dishes)
Each of these groups are responsible for a different tasks, all of which culminate in a customer receiving a meal. This is called concurrency. Dedicated work centers that can focus on individual tasks that when combined produce a result.
There is a limitation on the effectiveness of a restaurant if the restaurant only employs one person for each task. This is called serialization. If there is only a single server in a restaurant, then only one order can be taken at a time.
Parallelism is the ability to take the concurrent tasks and distribute them across multiple resources. In a restaurant, this would include servers, food prep, and cleaning. If there are multiple servers, then multiple orders can be taken at a time.
Each group is able to focus on their specific work center without having to worry about context switching, maximizing throughput, or minimizing latency.
Other examples of industries with concurrent work centers include factory workser, and assembly line workers. Essentially, any process that can be broken down into smaller repeatable tasks can be considered concurrent, and therefore can be parallelized when using proper concurrent design.
TL;DR: Concurrency enables correct parallelism, but parallelism is not necessary for concurrent code.6
Andrew S. Tanenbaum and Herbert Bos, Modern Operating Systems (Boston, MA: Prentice Hall, 2015), 517. ↩︎
Andrew S. Tanenbaum and Herbert Bos, Modern Operating Systems (Boston, MA: Prentice Hall, 2015), 86. ↩︎
Benchmarking Process Fork vs Thread Creation on Ubuntu 18.04 ↩︎