
Wow, did this guy run out of material already? I thought he was going to talk about AI, cybersecurity, and distributed computing. I had such high hopes.

I’m going to run through a quick recap of the evolution from single- to multi-core processing. This recap will likely be review for some of you, but the concepts here are going to be very important when we talk about mpdc.
Most importantly, it is critical to understand how the problem with single-core processing was solved. Although this solution didn’t solve the problem of speed per CPU core, it does inform our solution for scaling, which I’ll cover in my next post.
For anyone who wants a faster exit, here are some links to each section, in order.

Table Of Contents
Single-Core Processing
To a human, increases in processing speed are nearly invisible. Single-core processors were fast enough to seem like multiple events happened at the same time.
“I guess this guy never used Windows”
There was no actual parallel processing (where instructions are executed at the same time). In reality, the perceived “parallelism” was an illusion generated by operating systems that use tricks for scheduling processes, such as multi-threading and pipelining.
The OS would give the CPU some instructions, then after a time it would pause those instructions. Next, it would switch to a different set of instructions and give them CPU time. Rinse and repeat. Only one process would actually be running at a time, but it is so fast the human brain can’t perceive it.
But why should we care about this ancient technology? Because it’s important to understand how the performance bottleneck was solved. It gives us insight into how to solve similar problems where the scale is far greater (e.g., MPDC).
The Law Of Diminishing Returns

Real quick let’s go over a concept that is really important to understanding life and its application with regards to single-core processors.
“Oh geez, here we go. Giving life advice now, eh?”
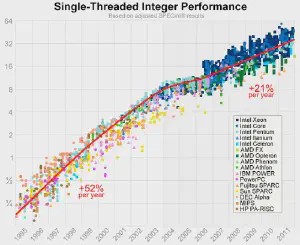
The Law of Diminishing Returns1 essentially states that, assuming a finite amount of resources, the rate of return (or, in our case, available processing power) will have a dramatic immediate increase that levels out over time. This reduces the year-over-year improvements in processing power.
Using data from Preshing, “prior to 2004, [single-threaded floating-point CPU performance] climbed even faster than integer performance (51% per year), at 64% per year: a doubling period of 73 weeks. After that, it leveled off at the same 21% per year.2
This issue was actually brought up in 2005 by Herb Sutter in an article called “The Free Lunch Is Over: A Fundamental Turn Toward Concurrency in Software. ” Sutter goes into detail regarding CPU manufacturers at the time and what issues they were running into trying to increase single-core performance.
Theoretical Relativity Limits
These articles do not really explain why there are limitations in single processor computation, though. Dr. Tanenbaum has a more explicit explanation though.
“According to Einstein’s special theory of relativity, no electrical signal can propagate faster than the speed of light, which is about 30cm/nsec in vacuum and about 20cm/nsec in copper wire or optical fiber.”3
This implies a theoretical physical limitation to the amount of processing that can be minimized into a CPU. Although a 1-THz processor (for example) may be possible, it actually raises another fundamental issue, which is heat dissipation.3
So, how did they solve the problem?
Multi-Core and Multiple CPU Processing

The introduction of multi-core and multiple CPU systems have now become ubiquitous in computers for enterprises and consumer markets. Multi-core CPUs introduced multiple processors (cores) in a single chip. These sometimes have a shared cache between them, or they have their own. These multi-core CPUs can process different instructions sets on each core in parallel (i.e., at the same time).
The addition of parallel capabilities in processors was not something that software systems were initially designed to utilize. For a while, most applications expected the OS to handle the scheduling of parallel threads onto each available processor. However, this approach did not really allow individual applications to utilize the new capabilities afforded by multi-core processors since a singular application would still only be executing sequentially. The solution? Parallelization of applications.
Parallelization of Applications

Building parallelizable software can be complicated and requires an understanding of concepts such as race conditions, deadlocks, and shared resources. These important topics can be difficult to conceptualize and are considered more advanced topics in computing. But, the introduction of multi-core / processor system makes understanding them necessary.
Some programming languages (like Google Go) or software frameworks like Apache Spark abstract the parallelization of processing away for users so that it’s not as necessary to understand these parallelization principles. In fact, I’ll be covering the topic of concurrent design and best practices for Google Go in a future post.
Regardless, the ability to parallelize across multiple cores / CPUs helped to solve the problem of computational speed stagnation. However, there are still some caveats, namely that parallelization only addresses a subset of the real problem — the ever-increasing need for more speed. Multi-core processors do not have the same limitations that single-core processors have because you can always add more cores. The problem with multi-core processors is actually whether or not you can afford to add more cores. I’ll be covering this in my next post regarding scaling.
What’s the big deal?

I would say that multi-core processing actually exacerbated a different problem. Most formal education does not adequately cover the differences between building sequential software versus parallel software. Building software to take advantage of multi-core CPUs requires an understanding of parallel processing.
Parallel processing is more complicated in its function than sequential processes. Since sequential processes execute instructions one after the other they do not have any special rules that apply to shared memory or IO. A lack of rules is not the case for parallel systems. Because instructions can happen in parallel one must understand race conditions, deadlocks, and shared memory.
It is important to understand the evolution from single-core to multi-core in order to understand infrastructure scaling. In my next post, I’m going to cover Vertical vs. Horizontal scaling and the benefits / problems with each. These two posts will provide a solid basis of understanding for Massively Parallel Distributed Computing (MPDC).
Shephard, R.W., Färe, R. The law of diminishing returns. Zeitschr. f. Nationalökonomie 34, 69–90 (1974). https://doi.org/10.1007/BF01289147 ↩︎
Preshing, J, A Look Back at Single-Threaded CPU Performance. (2012) ↩︎
Andrew S. Tanenbaum and Herbert Bos, Modern Operating Systems (Boston, MA: Prentice Hall, 2015), 517. ↩︎ ↩︎