
So, we discussed different ways to scale your application. Now, let’s look at monolithic architectures and applications.
A monolithic application is one in which all of the functions of the application are part of the same artifact / application. This does not mean that the application itself is tightly coupled, but that the application generally runs as a whole on the same system.1

One of the biggest advantages of a monolithic architecture is that there is defined logical flow to the application that cannot be disrupted by messaging breakdowns. Since it is all contained on a single system, there are far less failure points and coordinating sequential processes are built-in. Essentially, you get to take advantage of direct coupling of your application because all of the code is right there.
With the increasing popularization of micro-services, monolithic applications have been given an undeservedly bad reputation, and the term “monolith” is regularly used as a slur.
Table Of Contents
Scaling
Can you scale a monolith?
Contrary to popular opinion, monolithic applications can be scaled multi-dimensionally… within reason.

Most microservice aficionados, though, will say something like this:
“a monolithic architecture is that it can only scale in one dimension … this architecture can’t scale with an increasing data volume”2
This statement is a gross mischaracterization of monolithic architectures. Firstly, nothing is ever this cut and dry. There are several ways to approach horizontal scaling, and microservices do not own the patent to this process.
How do you scale a monolith?
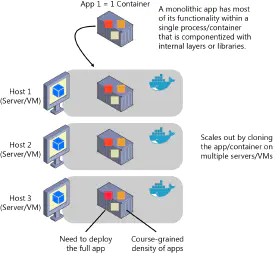 Since the entirety of the functionality of a monolithic application is contained
in a single software application, the means of scaling it usually involves
increasing the number of copies of that application running and placing them
behind a load balancer. This technique is usually the first and easiest way to
start scaling the application.
Since the entirety of the functionality of a monolithic application is contained
in a single software application, the means of scaling it usually involves
increasing the number of copies of that application running and placing them
behind a load balancer. This technique is usually the first and easiest way to
start scaling the application.
In actuality, though, it could be a combination of any of the options presented below. One example can be seen in the figure on the right where scaling occurs through the use of containerized monoliths.3
I would generally start with the following changes to scale a monolithic application:
1). Multiple Instances
- Setting up multiple instances of your application behind a load balancer can allow you to scale horizontally by directing traffic to multiple instances of the same application instead of a single application
- It is important to disperse these instances geographically based on your use case to ensure that, if one server or region goes down, the load balancer can pass requests to the rest of your instances after a failed health check
- If compatible, your application could be containerized and scaled through the use of DevOps and Kubernetes (K8s)
- These instances will likely still need to use the same database backend, which is covered below
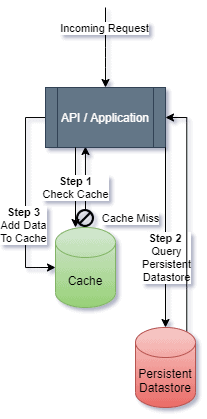
2). Caching Layer (i.e., Redis or Memcached)
- The application should first check here for data and update it with data if it didn’t exist in the cache after it pulls from the “slower” storage backend
- The cache should be set up with a reasonable time-to-live (TTL) value for data storage, so that it can properly manage memory overhead by auto-releasing cached values
- Caches come in all different forms and can drastically improve performance for multiple reads on the same values
- It is also important to mention that responding to the incoming request and Step 3 (adding data to the cache in the event of a cache miss) can happen in parallel
3). Geographically Localized High-Reliability Database (i.e., MongoDB or Cassandra)

- It is important that databases are correctly configured with read-only and write-only copies grouped near the same geographical locations as the application instances
- Applications will need to be updated appropriately to take advantage of the read-only or write-only database instances through routing logic (this can be abstracted in an application, or the database driver may do it automatically)
- High-Availability databases should also include a fail-over cluster so that, if it goes down, replicated databases are available as quickly as possible
- Understanding the database’s ability to shard data is also important. Sharding is when data is split horizontally between multiple instances of a database in chunks based on a pre-defined ordering scheme. For example, records may be split based on the alphabet or certain keys in the database may be hashed, and the hash may determine which instance should house that data.4
Pain Points and Problem Areas

Microservices start looking like a good alternative when you dig into the pain-points and problems with monolithic applications. There is a limit to how far a monolith can scale before you start running into serious issues. Not all of these problems are insurmountable, though, and microservices is only one solution, which may not be right for every application.
For example, if you’re using a monolithic application you are most likely stuck in a cycle of “deploy-all-the-things” whenever a new release is ready. Full application deploys are complex and can cause huge problems if there are issues in a release.
Planning for massive rollbacks in the event of a failure can almost take more time than the changes going into a release, and rollback preparations are often incomplete and untested. Creation of rollback scripts for the database, snapshots of the application servers (assuming it’s deployed on a VM), copies of the previous application release, and coordination among necessary teams are among a few of the required steps to prepare for rolling back monolithic applications.
The problems with deployment rollbacks is due to a fully-coupled application architecture. No individual piece of functionality can be deployed separate from anything else, no matter how small.
Heavy Dependency Structure
Since monoliths are singular self-contained applications, there are usually a large number of third-party dependencies. As the number of dependencies in an application increase, so does the risk of bugs and security vulnerabilities. The increase in bug and security risk is due to the fact that likely the greatest amount of source code in your application comes from those same third-party dependencies. The fact that it’s a monolithic application causes an application wide dependency on any third party library that is included. It is important to understand the pervasiveness of this dependency problem because it means that, even if that third party library is only used by a single piece of code, you are unable to de-couple it from the application.
The fact that there is such a high dependency overhead with monoliths leads to issues where even libraries that are used in the smallest ways cause you to have to re-deploy the full application when patching. Because of the massive amount of coupling caused by dependencies, teams will attempt to upgrade all dependencies at the same time. If the application does not have appropriate unit, integration, and regression tests in place, though, this will lead to more bugs and security vulnerabilities.
Heavy dependency structure that requires full application re-deploy is not ideal and is probably one of the greatest risks for a monolithic application from a security viewpoint because it leads to teams that never upgrade or patch dependencies, regardless of security vulnerabilities.
Code Change / Bug Risk Ratio
Related to dependency management, there is a high probability with every code change that a bug or multiple bugs will be added to an application. Introducing bugs in this way is not new, but it’s important to know that the greater the coupling in an application and the more monolithic the application, the greater the chance that a newly introduced bug will create issues throughout the application. This means that, as changes are made to a monolithic application, the introduction of technical debt increases drastically, and it is unlikely that even the best test suites will identify all of the issues before a new release.5678
Application Versioning and Downtime
Because monolithic applications are generally deployed completely as a singular application, they require downtime to release. Along with that need for downtime, there is only really one version for the application. Yes, different libraries can be different versions, but to upgrade a version of a library requires downtime for the application because the whole application must be re-deployed, just like we mentioned with regards to third-party libraries.
Should I Re-Architect My Application?
If your application functions within the current user base without issue and you have room to continue scaling vertically, then it probably does not make sense to re-architect and re-build your application right now. In other words, if 1) your application deployments are simple and generally unexciting, and 2) you have a good handle on technical debt and bug overhead, then you are probably doing ok.

If you expect within the next 12 to 18 months to exceed your ability to scale your application (available resources or money), then, yes. Take a baby-steps approach, though. Identify isolated functionality in your application and split it out.
The difference between Microservice and Service Oriented Architectures are primarily in the scale of functionality each process contains. So, for example, if you have a point of sale application, split out the inventory management part of the application into a service. Then move onto other functionality. You can always break down bigger modules later.
How far is too far?

It’s easy to go too far when making the move from a monolithic architecture to a microservice or service oriented architecture. There are advantages to both, and understanding where to stop is as important as knowing where to start. If you find that there are too many services to manage, then you should re-evaluate the number of microservices in your application. If there are too many dependencies on a single application and you are unable to scale, or your deployments are difficult, then consider breaking it up.
Original image taken by Patrickamackie2 (Patrick A. Mackie) Cropped and colour adjusted by Chainwit. – This file was derived from: Utah Monolith.jpg ↩︎
McCabe, Tom. 1976. “A Complexity Measure.” IEEE Transactions on Software Engineering, SE-2, no. 4 (December): 308-20 ↩︎
Shen, Vincent Y., et al. 1985. “Identifying Error-Prone Software–An Empirical Study.” IEEE Transactions on Software Engineering SE-11, no.4 (April): 317-24. ↩︎
Ward, William T. 1989. “Software Defect Prevention Using McCabe’s Complexity Metric.” Hewlett-Packard Journal, April, 64-68. ↩︎