

The Go programming language was created with concurrency as a first class citizen. It is a language that allows you to write programs that are highly parallel with ease by abstracting away the details of parallelism behind concurrency primitives1 within the language.
Most languages focus on parallelization as part of the standard library or expect the developer ecosystem to provide a parallelization library. By including the concurrency primitives in the language, Go, allows you to write programs that leverage parallelism without needing to understand the ins and outs of writing parallel code.
Table Of Contents
Concurrent Design
The designers of Go put heavy emphasis on concurrent design as a methodology which is based on the idea of communicating2 critical information rather than blocking and sharing that information.3
The emphasis on concurrent design allows for application code to be executed in sequence or in parallel correctly without designing and implementing for parallelization, which is the norm.4 The idea of concurrent design is not new and in fact a good example is the move from waterfall to agile development which is actually a move to concurrent engineering practices (early iteration, repeatable process).5
Concurrent design is about writing a “correct” program versus writing a “parallel” program.
Questions to ask when building concurrent programs in Go:
- Am I blocking on critical regions?
- Is there a more correct (i.e. Go centric) way to write this code?
- Can I improve the functionality and readability of my code by communicating?
If any of these are Yes, then you should consider rethinking your design to use Go best practices.
Communicating Sequential Processes (CSP)
The basis for part of the Go language6 comes from a paper by Hoare7 that discusses the need for languages to treat concurrency as a part of the language rather than an afterthought. The paper proposes a threadsafe queue of sorts which allows for data communication between different processes in an application.
If you read through the paper you will see that the channel primitive in Go is
very similar to the description of the primitives in the paper and in fact comes
from previous work on building languages based on CSP by Rob Pike.8
In one of Pike’s lectures he identifies the real problem as the “need [for] an approach to writing concurrent software that guides our design and implementation.”9 He goes on to say concurrent programming is not about parallelizing programs to run faster but instead “using the power of processes and communication to design elegant, responsive, reliable systems.”9
Concurrency through Communication

One of the most common phrases we hear from the creators of Go is:2 3
Don’t communicate by sharing memory, share memory by communicating.
- Rob Pike
This sentiment is a reflection of the fact that Go is based on CSP and the language has native primitives for communicating10 between threads (go routines).
An example of communicating rather than using a mutex to manage access to a shared resource is the following code:11
| |
Let’s take a look at the code and see what it does.
- Notice that this is not using the
syncpackage or any blocking functions. - This code only uses the Go concurrency primitives
go,select, andchan - Ownership of the shared resource is managed by the go routine. (Line 17)
- Even though the method contains a go routine, access to the shared resources does not happen in parallel. (Lines 30, and 34)
- The
selectstatement is used to check for read or write requests. (Lines 24, and 34) - A channel read from the incoming channel updates the value. (Line 24)
- A channel read from outside the routine executes a channel write to the outgoing channel with the current value of the shared resource. (Line 34)
Since there is no parallelism within the go routine itself the shared resource
is safe to access via the returned read-only
channel. In fact, the use of the select
statement here provides a number of benefits. The select
primitive section goes into more detail on this.
Blocking vs Communicating
Blocking12
- Stops process on critical section read / write
- Requires knowledge of the need for blocking
- Requires an understanding of how to avoid races and deadlocks
- Memory elements are shared directly by multiple processes/threads
Communicating12
- Critical data is shared on request
- Processes work when there is something to do
- Memory elements are communicated, not shared directly
Go’s Native Concurrency Primitives
Go Routines
What are Go Routines?
Go routines are lightweight threadlike processes which enable logical process
splitting similar to the & after a bash command4. Once the go routine is
split from the parent routine it is handed off to the Go runtime for execution.
Unlike the & in bash however these processes are scheduled for execution in
the Go runtime and not necessarily executed in parallel.4
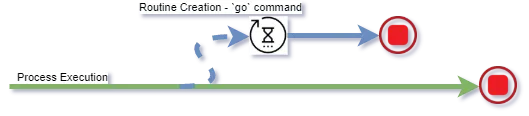 Figure 1: Example of a Go Routine
Process Split
Figure 1: Example of a Go Routine
Process Split
NOTE: The distinction here of “scheduled” is important because the Go runtime multiplexes the execution of go routines to improve performance on top of the operating system’s scheduling. This means that no assumptions can be made as to when the routine will execute.

Leaking Go Routines
Created by the go primitive, go routines are cheap, but its important to know
that they are not free.13 Cleaning up routines is important to ensure
proper garbage collection of resources in the Go runtime.
Time should be spent on designing with cleanup in mind. Ensuring that long running routines properly exit in the event of failure. It is also important to not create an unbounded number of go routines.
It is simple enough to spawn a go routine and because of that just using the
go primitive any time you want parallelization is tempting, but each routine
spawned has a minimum overhead of about 2kb.14 If your code creates too many
routines and they each have large overhead you can blow the stack. This is
incredibly difficult to debug in production environments because it is hard to
tell where the stack is overflowing and where the stack is leaking.
When a stack overflow occurs, the runtime will panic and the program will exit and each of the go routines will have stack information printed to standard error. This creates a great deal of noise in logs and is not very useful. Not only is the stack information not useful, but there is a huge amount of data that will be output (a log for every go routine, including it’s identifier and state). This is additionally difficult to debug because generally the log buffer on the operating system is likely too small to hold all of the stack information.
NOTE: In fairness, I have only seen this happen in production environments where the application was using >400,000 large go routines. This is most likely very uncommon and is not a problem for most applications.
TL;DR: Design go routines with the end in mind so that they properly stop when completed.13

Panicking in Go Routines
In general, panicking in a Go application is against best practices15 and
should be avoided. In lieu of panicking, you should return and handle errors
from your functions. However, in the event that using panic is necessary it is
important to know that panicking in a Go routine without a defer recover
(directly in that routine) will crash your application EVERY TIME.
BEST PRACTICE:
Do NOT Panic!
This is incredibly difficult to debug in a production environment because it
requires the stderr to be redirected to a file because it is likely your
application is running as a daemon. This is easier if you have a log aggregator
and it is set to monitor stderr, or the flat-file log. With Docker this is a bit
different, but it is still a problem.
Each Go routine needs its own
defer/recovercode16
1defer func() {
2 if r := recover(); r != nil {
3 // Handle Panic HERE
4 }
5}()
Channels
What are Channels in Go?
What is a channel?
Derived from the Communicating Sequential Processes paper by Hoare (1977)7 a channel is a communication mechanism in Go which supports data transfer in a threadsafe manner. It can be used to communicate between parallel go routines safely and efficiently without the need for a mutex.
Channels abstract away the difficulties of building parallel code to the Go runtime and provide a simple way to communicate between go routines. Essentially in it’s simplest form a channel is a queue of data.
In the words of Rob Pike: “Channels orchestrate; mutexes serialize.”17
How do Channels work in Go?
Channels are block by default. This means that if you try to read from a channel it will block processing of that go routine until there is something to read (i.e. data being sent to the channel). Similarly, if you try to write to a channel and there is no consumer for the data (i.e. reading from the channel) it will block processing of that go routine until there is a consumer.
There are some very important behaviors surrounding channels in Go. The Go runtime is designed to be very efficient and because of that if there is a Go routine which is blocked on a channel read or write the runtime will sleep the routine while it waits for something to do. Once the channel has a producer or consumer it will wake up the blocked routine and continue processing.
This is very important to understand because it allows you to explicitly leverage the CPU contention of the system through the use of channels.
NOTE: A
nilchannel will ALWAYS block.
Closing a Channel
When you are done with a channel it is best practice to close it. This is done
using the close function on the channel.
Sometimes it may not be possible to close a channel because it will cause a panic elsewhere in your application (due to a channel write on a closed channel). In that situation when the channel goes out of scope it will be garbage collected.
1 // Create the channel
2 ch := make(chan int)
3
4 // Do something with the channel
5
6 // Close the channel
7 close(ch)
If the channel is limited to the same scope (i.e. function) you can use the
defer keyword to ensure that the channel is closed when the function returns.
1 // Create the channel
2 ch := make(chan int)
3 defer close(ch) // Close the channel when func returns
4
5 // Do something with the channel
When a channel is closed it will no longer be able to be written to. It is very important to be mindful of how you close channels because if you attempt to write to a closed channel the runtime will panic. So closing a channel prematurely can have unexpected side effects.
After a channel is closed it will no longer block on read. What this means is
that all of the routines that are blocked on a channel will be woken up and
continue processing. The values returned on the read will be the zero values
of the type of the channel and the second read parameter will be false.
1 // Create the channel
2 ch := make(chan int)
3
4 // Do something with the channel
5
6 // Close the channel
7 close(ch)
8
9 // Read from closed channel
10 data, ok := <-ch
11 if !ok {
12 // Channel is closed
13 }
The ok parameter will be false if the channel is closed in the example above.
NOTE: Only standard and write-only channels can be closed using the
closefunction.
Types of Channels
There are a few different types of channels in Go. Each of them have different benefits and drawbacks.
Unbuffered Channels
1 // Unbuffered channels are the simplest type of channel.
2 ch := make(chan int)
To create an unbuffered channel you call the make function, supplying the
channel type. Do not provide a size value in the second argument as seen in
the example above and voila! You have an unbuffered channel.
As described in the previous section, unbuffered channels are block by default, and will block the go routine until there is something to read or write.
Buffered Channels
1 // Buffered channels are the other primary type of channel.
2 ch := make(chan int, 10)
To create a buffered channel you call the make function, supplying the channel
type and the size of the buffer. The example above will create a channel with a
buffer of size 10. If you attempt to write to a channel that is full it will
block the go routine until there is room in the buffer. If you try to read from
a channel that is empty it will block the go routine until there is something to
read.
If however you want to write to the channel and the buffer has space available it will NOT block the go routine.
NOTE: In general, only use buffered channels when you absolutely need to. Best practice is to use unbuffered channels.
Read-Only & Write-Only Channels
One interesting use case for channels is to have a channel that is only used for reading or writing. This is useful for when you have a go routine that needs to read from a channel but you do not want the routine write to it, or vice versa. This is particularly useful for the Owner Pattern described below.
This is the syntax for creating a read-only or write-only channel.
1 // Define the variable with var
2 var writeOnly chan<- int
3 var readOnly <-chan int
4
5 mychan := make(chan int)
6
7 // Assign the channel to the variable
8 readOnly = mychan
9 writeOnly = mychan
The arrows indicate the direction of the channel. The arrow before chan is
meant to indicate the flow of data is into the channel whereas the arrow after
chan is meant to indicate the flow of data is out of the channel.
An example of a read-only channel is the time.Tick method:
1 // Tick is a convenience wrapper for NewTicker providing access to the ticking
2 // channel only
3 func Tick(d Duration) <-chan Time
This method returns a read-only channel which the time package writes to
internally at the specified interval. This pattern ensures that the
implementation logic of ticking the clock is isolated to the time package
since the user does not need to be able to write to the channel.
Write-only channels are useful for when you need to write to a channel but you know the routine does not need to read from it. A great example of this is the Owner Pattern described below.
Design Considerations for Channels
It is important to think about the use of channels in your application.
Design Considerations include:
- Which scope owns the channel?
- What capabilities do non-owners have?
- Full ownership
- Read-Only
- Write-Only
- How will the channel be cleaned up?
- Which go routine is responsible for cleaning up the channel?
Owner Pattern
The Owner Pattern is a common design pattern in Go and is used to ensure that ownership of a channel is correctly managed by the creating or owning routine. This allows for a routine to manage the full lifecycle of a channel and ensure that the channel is properly closed and the routine is cleaned up.
Here is an example of the Owner Pattern in Go:
| |
Benefits:
- NewTime Controls the channel instantiation and cleanup (Lines 2, and 5)
- Enforces good hygiene by defining read-only/write-only boundaries
- Limits possibility of inconsistent behavior
Important notes about this example. The ctx context is passed to the function
NewTime and is used to signal the routine to stop. The tchan channel is a
normal unbuffered channel but is returned as read-only.
When passed to the internal Go routine, the tchan channel is passed as a
write-only channel. Because the internal Go routine is supplied with a
write-only channel it has the responsibility to close the channel when it is
done.
With the use of the select statement the time.Now() call is executed only on
a read from the channel. This ensures that the execution of the time.Now()
call is synchronized with the read from the channel. This type of pattern helps
minimize CPU cycles pre-emptively.
Looping over Channels
One method of reading from a channel is to use a for loop. This can be useful
in some cases.
1 var tchan <-chan time.Time
2
3 for t := range tchan {
4 fmt.Println(t)
5 }
There are a couple of reasons I do not recommend this approach. First, there is no guarantee that the channel will be closed (breaking the loop). Second, the loop does not adhere to the context meaning that if the context is canceled the loop will never exit. This second point is especially important because there is no graceful way to exit the routine.
Instead of looping over the channel I recommend the following pattern where you
use a infinite loop with a select statement. This pattern ensures that the
context is checked and if it is canceled the loop exits, while also allowing the
loop to still read from the channel.
1 var tchan <-chan time.Time
2
3 for {
4 select {
5 case <-ctx.Done(): // Graceful exit
6 return
7 case t, ok := <-tchan: // Read from the time ticker
8 if !ok { // Channel closed, exit
9 return
10 }
11 fmt.Println(t)
12 }
13 }
I discuss this method and the select statement in more detail in the Select
Statement section.
Forwarding Channels
Forwarding channels from one to another can also be a useful pattern in the
right circumstances. This is done using the <- <- operator.
Here is an example of forwarding one channel into another:
1func forward(ctx context.Context, from <-chan int) <-chan int {
2 to := make(chan int)
3
4 go func() {
5 for {
6 select {
7 case <-ctx.Done():
8 return
9 case to <- <-from: // Forward from into the to channel
10 }
11 }
12 }()
13
14 return to
15}
NOTE: Using this pattern you are unable to detect when the
fromchannel is closed. This means that thefromchannel will continually send data to thetochannel and the internal routine will never exit causing a flood of zero value data and a leaking routine.
Depending on your use case this could be desirable, however, it is important to note that this pattern is not a good idea when you need to detect a closed channel.
Select Statements
The select statement allows for the management of multiple channels in a Go
application and can be used to trigger actions, manage data, or otherwise create
logical concurrent flow.
1select {
2case data, ok := <- incoming: // Data Read
3 if !ok {
4 return
5 }
6
7 // ...
8
9case outgoing <- data: // Data Write
10 // ...
11
12default: // Non-blocking default action
13 // ...
14}
One important caveat to the
selectstatement is that it is stochastic in nature. Meaning that if there are multiple channels that are ready to be read from or written to at the same time, theselectstatement will randomly choose one of the case statement to execute.18
Testing Select Statements
The stochastic nature of the select statement can make testing select statements a bit tricky, especially when testing to ensure that a context cancellation properly exits the routine.
Here is an example of how to test the select statement using a statistical test where the number of times the test executes ensures that there is a low statistical likelihood of the test failing. This allows for additional coverage and ensures that the test is not flaky.
This test works by running the same cancelled context through a parallel routine 100 times with only one of the two contexts having been cancelled. In this situation there is always a consumer of the channel so there is a 50% likelyhood each time the loop runs that the context case will be executed.
By running 100 times with a 50% chance of the select tripping the context case there is a very, very low chance that the test will fail to detect the context cancellation for all of the 100 tests.
Work Cancellation with Context
In the early days of building Go applications users were building out
applications with a done channel where they would create a channel that looked
like this: done := make(chan struct{}). This was a very simple way to signal
to a routine that it should exit because all you have to do is close the channel
and use that as a signal to exit.
1// Example of a simple done channel
2func main() {
3 done := make(chan struct{})
4
5
6 go doWork(done)
7
8 go func() {
9 // Exit anything using the done channel
10 defer close(done)
11
12 // Do some more work
13 }()
14
15 <-done
16}
17
18func doWork(done <-chan struct{}) {
19 for {
20 select {
21 case <-done:
22 return
23 default:
24 // ...
25 }
26 }
27}
This pattern became so ubiquitous that the Go team created the context
package as a replacement. This package
provides an interface context.Context that can be used to signal to a routine
that it should exit when listening to the returned read-only channel of the
Done method.
1 import "context"
2
3 func doWork(ctx context.Context) {
4 for {
5 select {
6 case <-ctx.Done():
7 return
8 default:
9 // ...
10 }
11 }
12}
Along with this they provided a few methods for creating hierarchical contexts, timeout contexts, and a context that can be cancelled.
context.WithCancel- Returns a
context.Contextas well as acontext.CancelFuncfunction literal that can be used to cancel the context.
- Returns a
context.WithTimeout- Same returns as
WithCancelbut with a background timeout that will cancel the context after the specifiedtime.Durationhas elapsed.
- Same returns as
context.WithDeadline- Same returns as
WithCancelbut with a background deadline that will cancel the context after the specifiedtime.Timehas passed.
- Same returns as
BEST PRACTICE:
The first parameter of a function that accepts a context should always be the context, and it should be namedctx.